Qwen2.5-VL: Open Source Vision & Video Understanding
The Next Evolution in Vision-Language AI
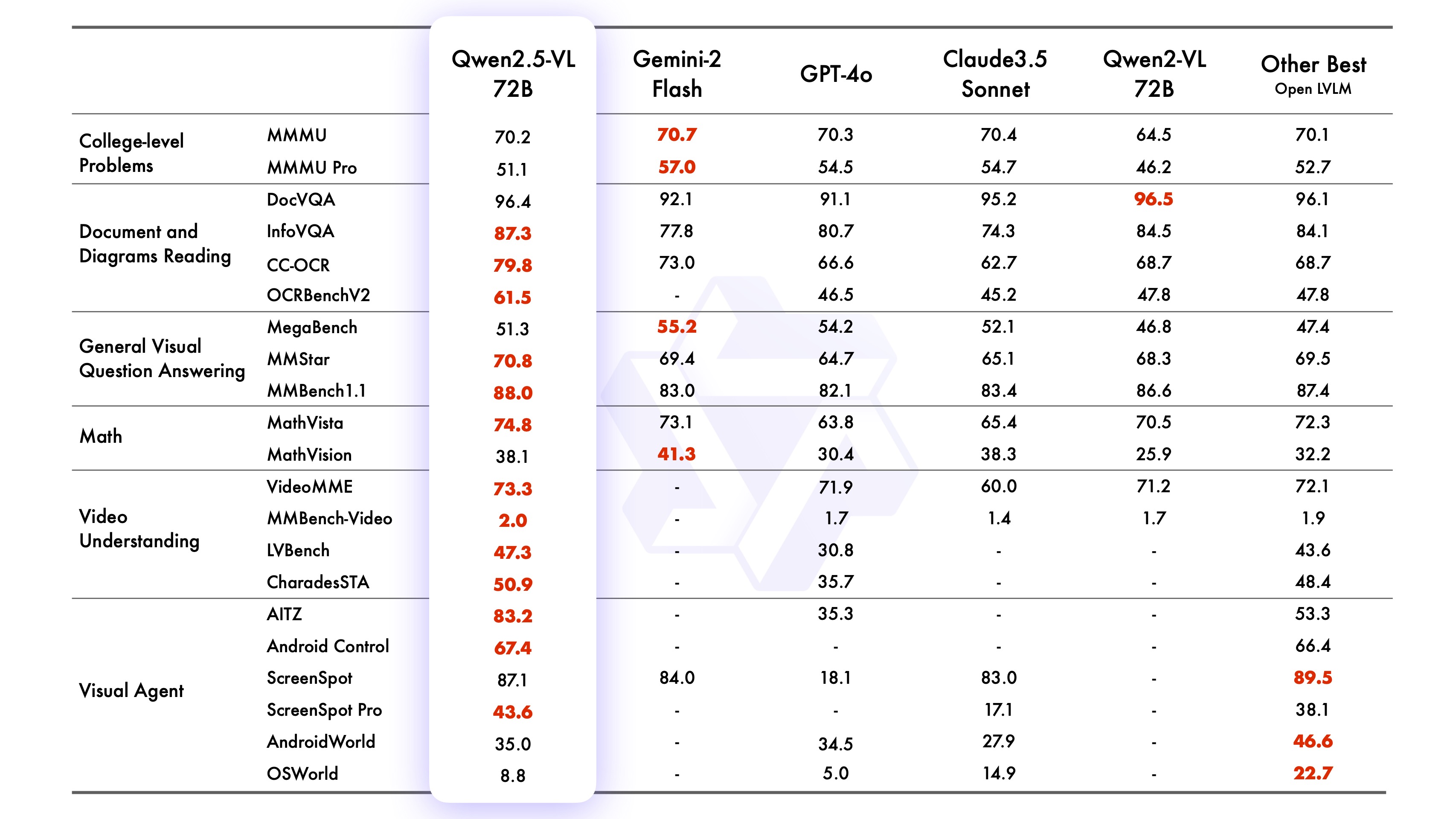
The AI landscape just got more interesting with Qwen's release of their latest vision-language model, Qwen2.5-VL. This isn't just another incremental update - it's a fundamental leap forward in how AI systems process and understand visual information. The release includes both base and instruct models in three sizes: 3B, 7B, and 72B parameters, all available on both Hugging Face and ModelScope.
Core Capabilities: Advanced Vision, Video, and Interface Understanding
What makes Qwen2.5-VL particularly exciting is its comprehensive approach to visual and video understanding. The model demonstrates impressive capabilities across multiple domains - from recognizing complex visual elements to processing hour-long videos with temporal precision.
One of the most striking features is its video processing capability. While several commercial models offer video understanding, Qwen2.5-VL stands out in the open-source landscape by supporting videos over an hour in length - a capability that was previously rare in openly available models. The implementation of dynamic frame rate training and absolute time encoding allows for second-level event localization within these long videos. This means the model can not only understand the content but pinpoint specific moments and events within the timeline - a crucial feature for video analysis and content management systems.
This capability opens up exciting possibilities for automation and assistance. Whether it's helping users navigate complex software interfaces or automating repetitive tasks across different applications, Qwen2.5-VL can understand context and take appropriate actions. This level of interface interaction has been primarily limited to commercial models until now, making its presence in an open-source model particularly noteworthy.
I'll be testing these interface capabilities alongside the video processing on consumer hardware (specifically an RTX-4090) to see how well they scale in practical applications. The ability to run these advanced features on local hardware could revolutionize how we think about AI assistance in daily computing tasks.
Document Processing: Bridging Old and New
In addition to its core visual capabilities, Qwen2.5-VL brings interesting advances to document understanding. The model parses complex documents with a unique HTML-based format they call "QwenVL HTML", handling everything from academic papers and technical diagrams to complex layouts in magazines and mobile app screenshots.
An interesting aspect here is how Qwen2.5-VL can complement rather than replace traditional OCR systems. While modern vision-language models are impressive, there's still value in combining them with battle-tested OCR tools that have been optimized over decades for specific use cases. For instance, you might use traditional OCR for high-speed text extraction from standardized documents, while leveraging Qwen2.5-VL for understanding the context, layout, and visual elements that give that text meaning. This hybrid approach could be particularly powerful in enterprise settings where you need both reliability and advanced understanding.
The Technical Breakthroughs
The real innovation comes in three key areas:
The implementation of dynamic frame rate training and absolute time encoding allows for second-level event localization within these long videos. This means the model can not only understand the content but pinpoint specific moments and events within the timeline - a crucial feature for video analysis and content management systems.
I'll be testing these video capabilities on consumer hardware (specifically an RTX-4090) to see how well they scale in practical applications. The ability to process hour-long videos on local hardware could be a game-changer for developers working on video analysis tools, particularly in scenarios where cloud processing isn't feasible due to privacy concerns or bandwidth limitations.
Looking Forward
The release of Qwen2.5-VL signals a shift in how we think about multimodal AI. It's not just about making models bigger - it's about making them smarter and more efficient. The team's focus on temporal and spatial understanding, combined with their innovative approach to visual encoding, suggests we're entering a new era of AI that can truly understand the visual world in context.
This release is particularly significant for developers working on applications that need to process complex visual information. Whether you're building document processing systems, video analysis tools, or complex visual agents, Qwen2.5-VL provides a robust foundation that's both powerful and accessible.
The future roadmap suggests even more exciting developments ahead, with plans to enhance problem-solving capabilities and incorporate additional modalities. We're moving closer to the dream of truly omni-capable AI models that can seamlessly handle multiple types of input and tasks.
Note: Keep an eye on the Hugging Face and ModelScope repositories for the latest updates and implementations of Qwen2.5-VL. The rapid pace of development in this space means we'll likely see even more capabilities and optimizations in the coming months.